Old Android View State Machine Part 1
State representations are essential to our software systems/applications, but more importantly, where this data comes from and the various transformation processes that occur before reaching the final checkpoint. A data store that can be retrieved later.
Note that the term “state” is used freely here. Here, the term state relates to the set of data that will be displayed in the view. state object
status marker
I have this term I call status marker, Described as an indicator of a data object that is used to compute a state or represents the state itself. Let’s take a closer look at this.
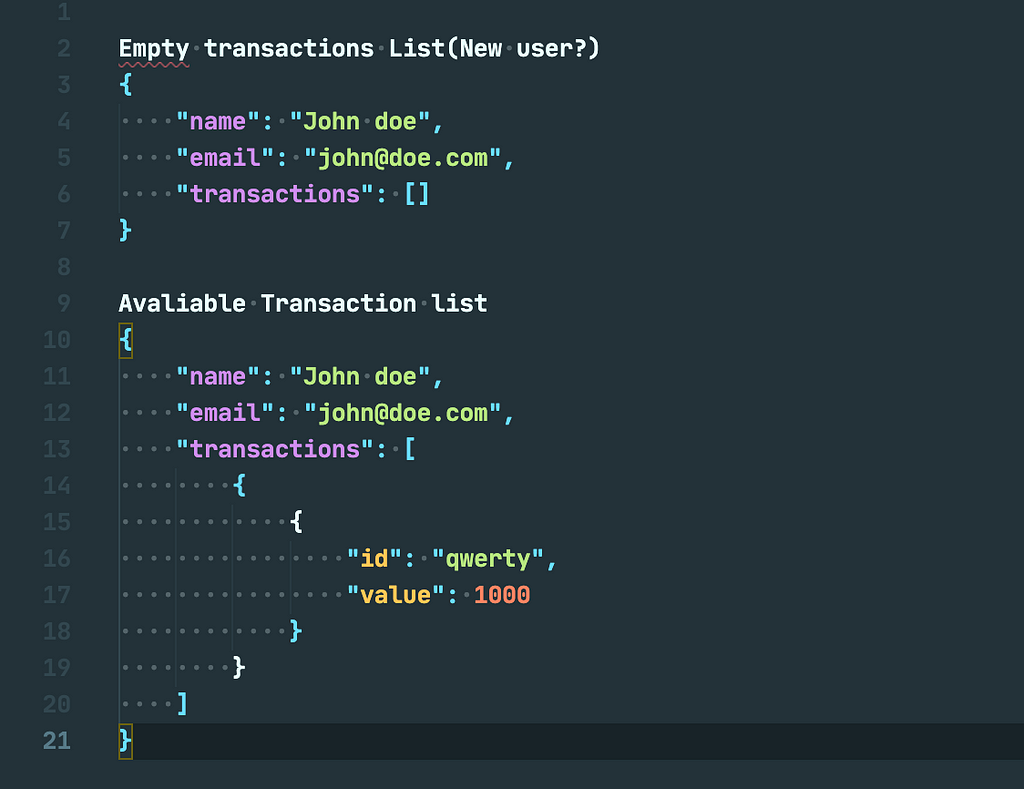
Looking at this sample JSON data, the first sample represents users without transactions and the second sample has a list of transactions. If you have a screen that needs to display a list of user transactions, you probably have a UI state machine that either displays an empty state when there are no transactions, or displays a list of user transactions. now without mapping task JSON key is our “Status Marker” for This sample JSON. This is just a simple representation and as we know there are different ways to create a state marker, some representations deal with using things like enums or sealed classes, even boolean flags with specific keys. We now use State Markers in terms of returning server data and identifying markers without any post-processing.
A more realistic scenario would typically have status markers with a mix of different properties and would require multi-step checks against keys available in objects in the server response or in-device database.
https://medium.com/media/ff0619cd1bf1696fa49cf42a18ab7400/href
In these scenarios, we define state as a combination of different data properties or the absence of a specific value, and the processing of this data and the allocation or creation of the contained state data can be viewed as a state pipeline.
Success and error status
When a service requests data, it typically expects to succeed in one of two states when this response is the start of a data pipeline process and it receives either a happy path datatype or an error (unhappy path) regardless of the path. Contains specific markers for states within the path flow.
The returned data path (happy or sad) determines the type cast to apply to that data until it gets the final state data object.
Let’s talk about error states. In most cases, errors always have the most obvious marker, and the representation of errors for views within a state machine is almost always very simple. Let’s say you make a request from a mobile device and throw an exception. The exception tells you which error state to switch to.
https://medium.com/media/4f04786d623e54b92bfa77c8dbbac2d1/href
Above we have 2 substates of error which we can map to one of them depending on the response. That is, for any error on the server, you can map it to a generic error, or to a connection to an internet-related issue.
https://medium.com/media/de600d3a5455795eb262ff83450a2e3b/href
A simple approach to mapping the error to the error ViewState. Here we are using the Throwable/Exception type as StateMarker, so when an IOException is thrown, ConnectivityErrorState is raised and other exceptions are marked as GeneralError. These mappings are always application specific and are shown only as examples of how error markers can be converted to a StateMachine for View. Unlike the happy path of finding markers within data objects like enums, booleans, ints, or certain string combinations that usually determine what kind of state the user is in, imperfect details mean that the data belongs to. For new users?
https://medium.com/media/ef20c8ffb011f7fbf23fa125999f5b07/href
State Pipeline Happy Path
If you are going down the happy path of getting a successful data response from the service, your next step is usually to clean up this data and remap the object to an object that is more easily associated with your view. Basically, I like to use sealed classes to represent state data and attach related data as parameters. This makes it easier to switch the logic for the returned state and get the data while only accessing specific fields that are available. , in more complex scenarios I would prefer to do additional processing in the pipeline with stateful widgets. After the sealed class children represent the view and map to these widgets, the final emitted object is attached to the view.
https://medium.com/media/fe8408c579c102817f8c5d720a778f85/href
Above we have a simple view state that represents an empty view and a data view. The expected picture is that it receives the data, an intermediate mapper transforms it into one of the listed states, and then consumes the final object in the view.
https://medium.com/media/f2cbbbedce6006c272ffebaa01f00605/href
Creating a mapper allows us to leverage what we’ve assumed. “Status Marker” Availability of the list of transactions in this case, returning an EmptyView status if the list is empty. In more complex applications, one mapper can feed data to another. This is usually done as the state markers of that system arise from the calculation or separation of various properties until the required data/assumption state is reached.
Note: Creating mappers as objects makes it easier to test these mappers and see their output without having to add a lot of initial setup.
When it comes to data mapping in general, most people map across layers of the system, so Data -> Domain -> Presentation or Data -> Presentation, map to domains only when the cache is needed. This is subjective to the architecture of the application, as it is not uncommon to find a domain object used in a view for presentation. Whichever step process you use, always try the following:
- Identify the states that a perspective or system may belong to and create the necessary representations to process this data.
- Separate state logic in presentation/view. This helps you to easily follow your state logic as you code and think about your data flow.
- Never return data from an object that will never be used. As in the state example above, the EmptyState is basically a screen with some kind of image/picture, so the EmptyView object doesn’t need to return any user data.
Here, our pipeline is summarized as a group of mappers or subprocesses that take on data to identify, allocate, and create or create stateful objects that may contain associative data.
in short…
- Transitions between states of data are based on a series of transformations defined by various markers in a data object or set.
- Identify or conceptualize multiple finite states (A superclass with a subclass of state), including the happy-sad paths (error and success responses) not only makes it easy to handle the various transitions between states, but adding a new state simply adds a set of transformations to that view that will map to this new state.
- Having a single source for emitting state data in a view helps to maintain a clear logical representation of view transitions.
Android View State Machine Part 2: State Data Generation and Pipeline was originally posted on ProAndroidDev on Medium, where people continue the conversation by highlighting and responding to this story.

/https://specials-images.forbesimg.com/imageserve/619e82f4a55c1d2f42025b70/0x0.jpg)
{kind=link}